- Primary Target Group
- Alternative Target Group

For the magic of automatic failover to occur, we need a lambda function to swap out the target groups and we something to trigger the lambda function. The trigger is going to be a Cloudwatch Alarm that sends a notification to SNS. When the SNS notification is triggered, the lambda function will run. First, you will need an SNS Topic. My screenshot already has the Lambda function already bound, but this will happen automatically as you go through the Lambda function set up. Screenshot of SNS Notification.
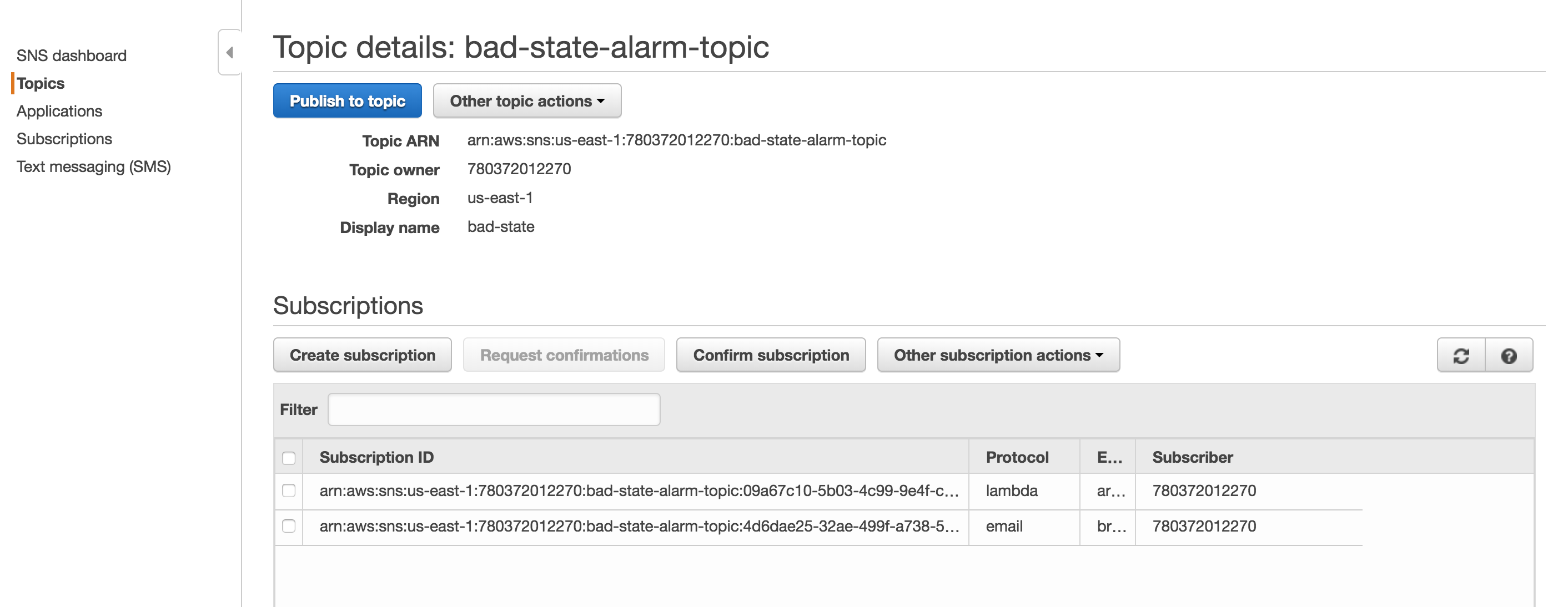
Second, create a Cloudwatch alarm like the one below. Make sure to select the topic configured previously. The Cloudwatch Alarm will trigger when there are less than 1 healthy hosts. Screenshot of the Cloudwatch Alarm [gallery ids="436,437" type="rectangular"] Third, we finally get to configure the Lambda function. You must ensure that your lambda function has sufficient permissions to make updates to the ALB. Below is the JSON for an IAM role that will allow the Lambda function to make updates to any ELB.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "elasticloadbalancing:*",
"Resource": "*"
}
]
}
from __future__ import print_function
import boto3
print('Loading function')
client = boto3.client('elbv2')
def lambda_handler(event, context):
try:
response_80 = client.modify_listener(
# This is the HTTP (port 80) listener
ListenerArn = 'arn:aws:elasticloadbalancing:region:id:listener/app/alb/id/id',
DefaultActions=[
{
'Type': 'forward',
'TargetGroupArn': 'arn:aws:elasticloadbalancing:region:id:targetgroup/id/id'
},
]
)
response_443 = client.modify_listener(
# This is the HTTPS (port 443) listener
ListenerArn='arn:aws:elasticloadbalancing:region:id:listener/app/alb/id/id',
DefaultActions=[
{
'Type': 'forward',
'TargetGroupArn': 'arn:aws:elasticloadbalancing:region:id:targetgroup/id/id'
},
]
)
print(response_443)
print(response_80)
except Exception as error:
print(error)

After putting it all together. When there are less than 1 health target group members associated with the ALB the alarm is triggered and the default target group will be replaced with the alternate backup member. I hope this helps!
Cheers,
BC

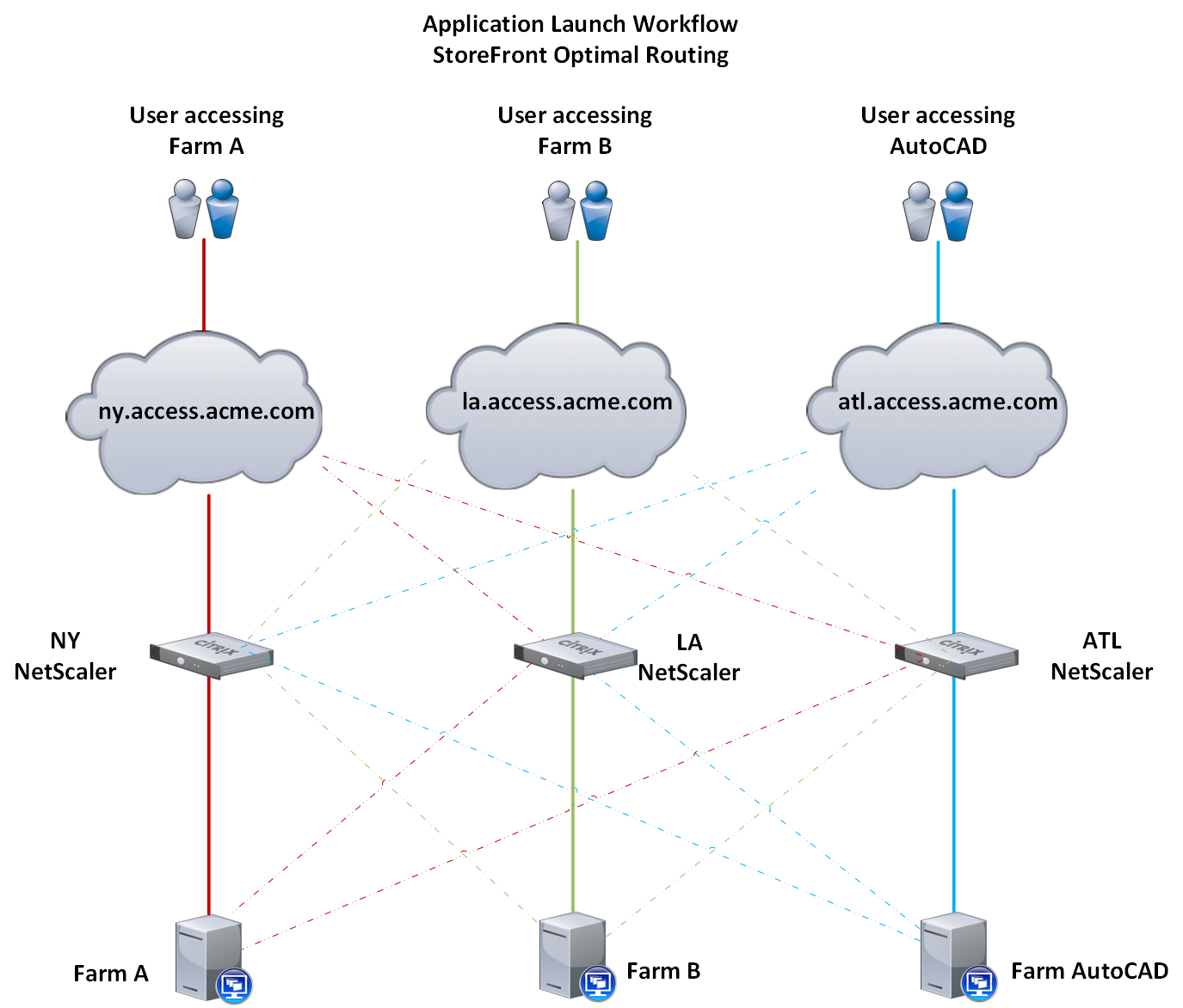
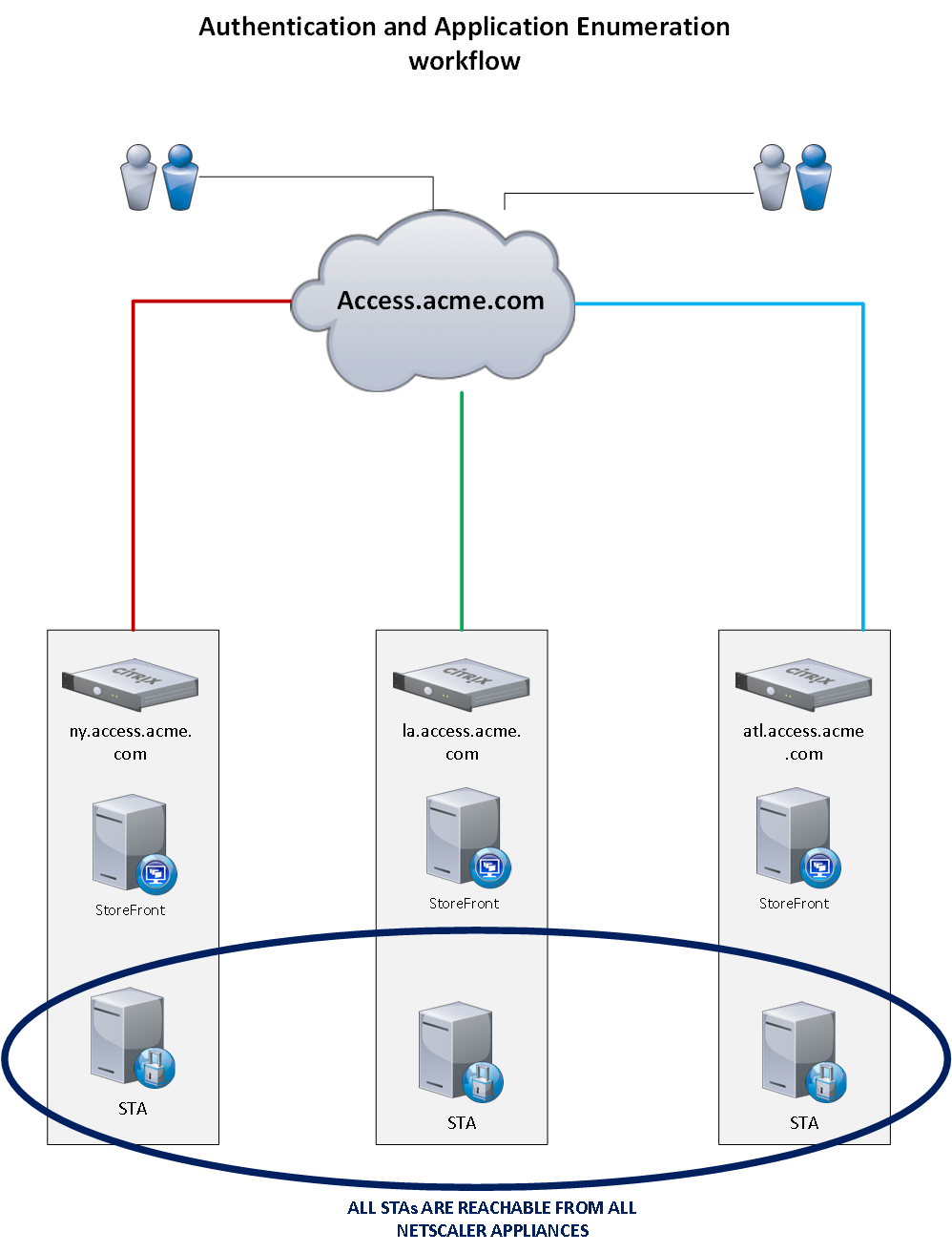 The diagram below illustrates the application launch workflow. The thick lines represent normal working conditions. The dotted lines represent the backup workflow in the event that site is experiencing an outage.
The diagram below illustrates the application launch workflow. The thick lines represent normal working conditions. The dotted lines represent the backup workflow in the event that site is experiencing an outage.
 Thank you for reading. I hope you found this beneficial. Please let me know if you have questions in the comments below.
BC
Thank you for reading. I hope you found this beneficial. Please let me know if you have questions in the comments below.
BC
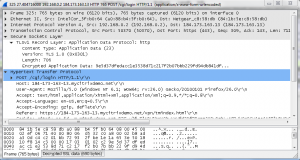
 If no issues are found at the queried XML Broker, then the script will wait 5 seconds and move to the next XML Broker in the list. If you need to manually stop the script, then use CTRL+C or just close the window where the application is being executed. When an error is found, then I can logon on to the Director server and begin troubleshooting.
If no issues are found at the queried XML Broker, then the script will wait 5 seconds and move to the next XML Broker in the list. If you need to manually stop the script, then use CTRL+C or just close the window where the application is being executed. When an error is found, then I can logon on to the Director server and begin troubleshooting.
 Each query is targeted at the URL “/Citrix/Monitor/OData/v2/Data/FailureLogSummaries”. The first
Each query is targeted at the URL “/Citrix/Monitor/OData/v2/Data/FailureLogSummaries”. The first  FIPS NetScaler Appliances
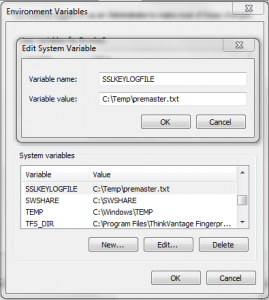
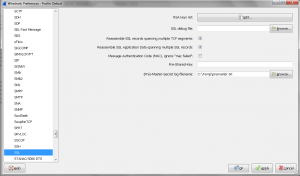
So what happens if you can’t access your private key to run OpenSSL commands (FIPS NetScaler appliances)? Remember that the Key, CSR, and Cert MUST all use the same modulus if they are related. With this theory in mind, you can generate a bogus CSR off of the FIPS key to see what the modulus should be for the public certificate. If you generate a CSR off of a FIPS box and the modulus for that CSR does not match the modulus for the Public Certificate that was returned to you, then that certificate did not use a CSR that was generated off of that FIPS key.
I hope this information has helped. The OpenSSL commands I have listed are only a handful of my favorites. For a really good cheat sheet on useful commands (I have it bookmarked), check out the link below.
FIPS NetScaler Appliances
So what happens if you can’t access your private key to run OpenSSL commands (FIPS NetScaler appliances)? Remember that the Key, CSR, and Cert MUST all use the same modulus if they are related. With this theory in mind, you can generate a bogus CSR off of the FIPS key to see what the modulus should be for the public certificate. If you generate a CSR off of a FIPS box and the modulus for that CSR does not match the modulus for the Public Certificate that was returned to you, then that certificate did not use a CSR that was generated off of that FIPS key.
I hope this information has helped. The OpenSSL commands I have listed are only a handful of my favorites. For a really good cheat sheet on useful commands (I have it bookmarked), check out the link below.
 The workflow above is all seamless to the user. From their perspective, they type connect.example.com, and that takes them to the resources they need to focus on their job.
Please keep in mind that this workflow is unique to Receiver for Web. Users that manually configure Receiver on the internal network will need to type out “int-connect.example.com” to connect to the StoreFront VIP and avoid a redirect. Again, I recommend using the provisioning file from StoreFront to configure the Native Receiver.
Let me know if you have questions in the comments below!
BC
The workflow above is all seamless to the user. From their perspective, they type connect.example.com, and that takes them to the resources they need to focus on their job.
Please keep in mind that this workflow is unique to Receiver for Web. Users that manually configure Receiver on the internal network will need to type out “int-connect.example.com” to connect to the StoreFront VIP and avoid a redirect. Again, I recommend using the provisioning file from StoreFront to configure the Native Receiver.
Let me know if you have questions in the comments below!
BC